

- -
-
۱۲ آذر ۱۴۰۰

نتایج حاصل از شبکههای عصبی از این ایده حمایت میکند که مغز از پیشبینی برای ایجاد ادراک استفاده میکند و علت انجام این کار، صرفهجویی در مصرف انرژی است.
اینکه چگونه مغز ما که توده سه پوندی از بافت محصور در جمجمهای استخوانی است، با استفاده از حواس، ادراک را ایجاد میکند، معمایی قدیمی است. شواهد فراوان و دههها پژوهش مداوم نشان میدهد مغز بهسادگی نمیتواند اطلاعات حسی را با هم ترکیب کند، مثل اینکه قطعات پازل پیچیدهای را درکنار هم قرار دهد، تا بتواند اطراف خود را درک کند. این امر با این واقعیت تأیید میشود که حتی زمانی که اطلاعات ورودی مبهم است، مغز میتواند صحنهای را براساس نوری که به چشمان ما وارد میشود، بسازد. درنتیجه، بسیاری از عصبشناسان، مغز را بهعنوان «ماشین پیشبینی» میبینند.
مغز ازطریق پردازش پیشبینانه (predictive processing) از دانش پیشین خود از جهان استفاده میکند تا درمورد علل اطلاعات حسی ورودی نتیجهگیری کند یا فرضیههایی ایجاد کند. این فرضیهها (و نه خود ورودیهای حسی) باعث ایجاد ادراک در چشم ذهن ما میشوند. هرچه ورودی مبهمتر باشد، میزان اتکا به دانش گذشته بیشتر است. فلوریس دی لانگ، عصبشناسی از دانشگاه رادبود هلند میگوید: «زیبایی چارچوب پردازش پیشبینانه در این است که دارای ظرفیت عظیمی برای توضیح بسیاری از پدیدههای مختلف در سیستمهای متفاوت است».
اگرچه شواهد روزافزون علوم اعصاب در حمایت از ایده پردازش پیشبینانه، عمدتا وابسته به شرایط بوده و توضیحات دیگر نیز میتوانند منطقی بهنظر برسند. تیم کیتزمن از دانشگاه رادبود که درزمینهی یادگیری ماشین و علوم اعصاب مطالعه میکند، میگوید: «اگر به علوم اعصاب شناختی و تصویربرداری عصبی در انسانها نگاه کنید، شواهد زیادی را میبینید، اما این شواهد بسیار ضمنی و غیرمستقیم هستند». بنابراین، پژوهشگران برای درک و آزمایش ایده مغز پیشبینیکننده به مدلهای محاسباتی روی آوردهاند.

وقتی تصور مبهمی به ما نشان داده میشود، آنچه درک میکنیم، میتواند به زمینه بستگی داشته باشد. برخی از دانشمندان علوم اعصاب این موضوع را بهعنوان شاهدی میدانند که نشان میدهد مغز ادراک خود را از بالا به پایین و با استفاده از پیشبینی درمورد آنچه انتظار دارد، ایجاد میکند.
عصبشناسان محاسباتی شبکههای عصبی مصنوعی را با طرحهایی الهامگرفته از رفتار نورونهای زیستی ساختهاند که یاد میگیرند درمورد اطلاعات دریافتی پیشبینی کنند. این مدلها تواناییهای شگفتانگیزی را نشان میدهند که بهنظر میرسد بهنوعی شبیه توانایی مغز واقعی باشد. برخی آزمایشها با این مدلها حتی اشاره میکنند که مغز باید بهعنوان ماشین پیشبینی تکامل پیدا کند تا محدودیتهای انرژی را جبران کند.
همراه با توسعه مدلهای محاسباتی، دانشمندان علوم اعصاب که حیوانات زنده را مطالعه میکنند، نیز درحال متقاعدشدن دراینباره هستند که مغز یاد میگیرد علت ورودیهای حسی را استنباط کند. درحالیکه جزئیات دقیق این موضوع که مغز چگونه این کار را انجام میدهد، مبهم است، کلیات آن درحال روشنتر شدن است.
استنباط ناخودآگاه در ادراک
پردازش پیشبینانه ممکن است ابتدا مانند مکانیسم غیرشهودی برای ادراک بهنظر برسد، اما دانشمندانی زیادی به آن روی آوردهاند، زیرا توضیحات دیگر دارای کاستی است. حتی هزار سال پیش، ابن هیثم، منجم و ریاضیدان مسلمان در کتاب المناظر (دانش نورشناسی) به شکلی از پردازش پیشبینانه اشاره کرد تا جنبههای مختلف بینایی را توضیح دهد.
ایدهی پردازش پیشبینانه در دهه ۱۸۶۰ قوت گرفت، زمانی که فیزیکدان و پزشک آلمانی، هرمان فون هلمهولتز استدلال کرد که مغز بهجای ایجاد ادراک پایین به بالا از ورودیهای حسی دریافتی، علتهای خارجی آن ورودیها را استنباط میکند.
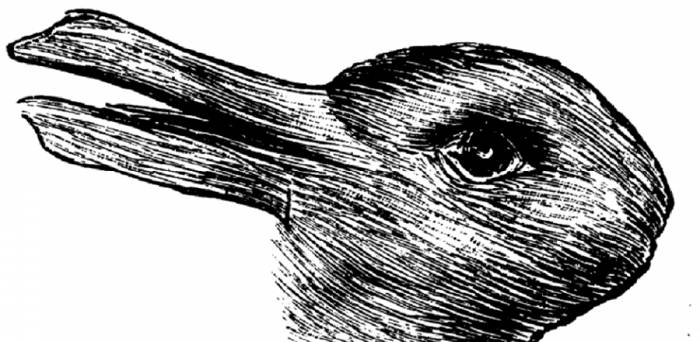
هلمهولتز، مفهوم «استنباط ناخودآگاه» را برای توضیح ادراک دوپایا یا چندپایا بیان کرد که در آن یک تصویر را میتوان به بیش از یک روش درک کرد. برای مثال، این پدیده با تصویر مبهم معروفی که میتوانیم آن را بهعنوان اردک یا خرگوش درک کنیم، اتفاق میافتد: ادراک ما بهطور پیوسته بین این دو تصویر درحال جابهجایی است. هلمهولتز اظهار داشت که در چنین مواردی، ادراک باید نتیجه فرایند ناآگاهانه استنباط از بالا به پایین درمورد علت دادههای حسی باشد، زیرا تصویری که روی شبکیه تشکیل میشود، تغییر نمیکند.
در طول قرن بیستم، روانشناسان شناختی به جمعآوری شواهد در این زمینه ادامه دادند که ادراک، فرایندی از ساخت فعالانه است که هم از ورودیهای ادراکی بالا به پایین و هم از ورودیهای حسی پایین به بالا استفاده میکند. این تلاش در مقاله تأثیرگذار سال ۱۹۸۰ با عنوان «ادراکات بهعنوان فرضیه» توسط ریچارد گرگوری فقید به اوج رسید. ریچارد گرگوری در مقالهی خود استدلال کرد که توهمهای ادراکی اساسا حدسهای اشتباه مغز درمورد علتهای برداشتهای حسی هستند.
در همین حین، دانشمندان بینایی کامپیوتر در تلاش برای استفاده از بازسازی پایین به بالا برای توانا ساختن کامپیوترها برای دیدن بدون استفاده از مدل مولد داخلی بهعنوان مرجع، سردرگم شدهاند. کارل فریستون، عصبشناس محاسباتی در دانشگاه کالج لندن میگوید: «تلاش برای پیدا کردن معنای دادهها بدون مدل مولد محکوم به شکست است و تنها کاری که میتواند انجام دهد این است که الگوی دادهها را مشخص کند».
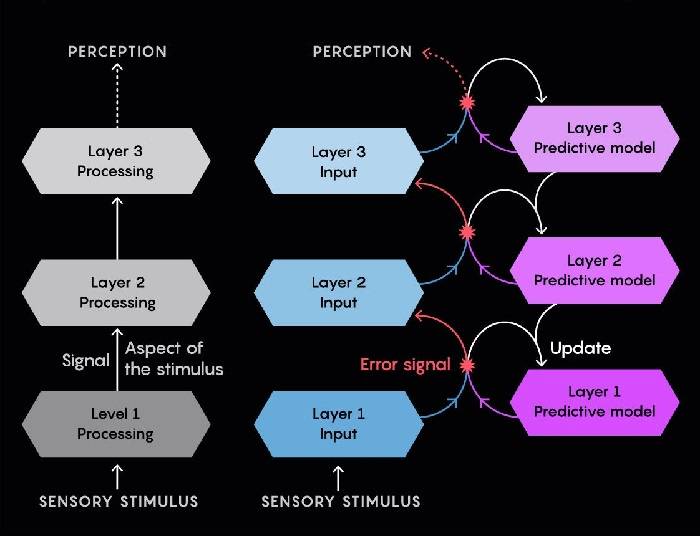
اما درحالیکه پذیرش پردازش پیشبینانه رشد کرده است، سوالاتی درمورد نحوه اجرای آن در مغز وجود دارد. مدل محبوبی که «کدگذاری مبتنی بر پیشبینی» یا «کدگذاری پیشبینانه» نام دارد، ادعا میکند که سلسله مراتبی از سطوح پردازش اطلاعات در مغز وجود دارد. بالاترین سطح، نشاندهندهی انتزاعیترین و دانش سطح بالا است (برای مثال، ادراک مار در سایههای پیشرو).
این لایه فعالیت عصبی لایه پایینی را با ارسال سیگنالها به پایین، پیشبینی میکند. لایه پایینی فعالیت واقعی خود را با پیشبینی رسیده از بالا مقایسه میکند. اگر عدم تطابق وجود داشته باشد، لایه سیگنال خطایی ایجاد میکند که به سمت بالا جریان پیدا میکند، بهطوریکه لایه بالاتر بتواند نمایشهای داخلی خود را تصحیح کند. این فرایند بهطور همزمان، برای هر جفت لایه متوالی، تا پایینترین لایه که ورودیهای حسی واقعی را دریافت میکند، اتفاق میافتد.
هرگونه اختلافی بین آنچه از جهان دریافت میشود و چیزی که پیشبینی میشود، به سیگنال خطایی منجر میشود که کل سلسله مراتب را طی میکند. بالاترین لایه درنهایت فرضیه خود را تصحیح میکند (که این اصلا مار نبود و فقط طناب تاخوردهای روی زمین بود).
ادراک مبتنیبر پیشبینی: مدلهای «پایین به بالا» از ادراک نسبتبه مدلهای «بالا به پایین» که در آنها لایههای نورونی دارای سلسله مراتب در مغز درمورد محرک حسی که دریافت خواهند کرد، پیشبینی انجام میدهند، کمتر موفق بودهاند. مدل پایین به بالا: ادراک از سیگنالهای حسی ایجاد میشود که ازطریق سلسله مراتبی از لایههای پردازنده عصبی به سمت بالا حرکت میکند. مدل بالا به پایین: هر لایه پیشبینیهایی از ورودیهایی که دریافت خواهد کرد، به لایه زیرین خود میفرستد. بهروزرسانیهایی درمورد خطاهای پیشبینی به سمت بالا فرستاده میشود تا مدل پیشبینانه لایه تصحیح شود. ادراک، حاصل ترکیب پردازش بالا به پایین و پردازش پایین به بالا است.
 دی لانگ میگوید: «بهطورکلی، ایدهی کدگذاری مبتنیبر پیشبینی این است که مغز اساسا دو جمعیت نورون دارد. یک جمعیت که بهترین پیشبینی فعلی را درمورد آنچه ادراک میشود، کدگذاری میکند و دیگری که خطاهای آن پیشبینی را ابلاغ میکند».
دی لانگ میگوید: «بهطورکلی، ایدهی کدگذاری مبتنیبر پیشبینی این است که مغز اساسا دو جمعیت نورون دارد. یک جمعیت که بهترین پیشبینی فعلی را درمورد آنچه ادراک میشود، کدگذاری میکند و دیگری که خطاهای آن پیشبینی را ابلاغ میکند».
در سال ۱۹۹۹، دانشمندان کامپیوتر، راجش رائو و دانا بالارد (در آن زمان بهترتیب در مؤسسه مطالعات زیستی و دانشگاه راچستر بودند)، مدل محاسباتی قدرتمندی را از کدگذاری پیشبینانه ایجاد کردند که دارای نورونهایی برای پیشبینی و تصحیح خطا بود. آنها قسمتهایی از مسیری در سیستم پردازش بصری مغز نخستیها را مدلسازی کردند که از مناطق سازمانیافته به شکل سلسلهمراتبی تشکیل شده است که مسئول تشخیص چهرهها و اشیاء است. آنها نشان دادند که این مدل میتواند برخی رفتارهای غیرعادی سیستم بینایی نخستیها را تکرار کند.
اگرچه پژوهش فوق پیش از پیدایش شبکههای عصبی عمیق مدرن انجام شد که دارای یک لایه ورودی، یک لایه خروجی و چند لایه پنهان هستند که بین این دو لایه قرار دارند.
تا سال ۲۰۱۲، عصبشناسان از شبکههای عصبی عمیق برای مدلسازی جریان بصری شکمی نخستیها استفاده میکردند. اما تقریبا همه این مدلها از نوع «شبکههای پیشخور» بودند که در آن اطلاعات فقط از جهت ورودی به خروجی جریان دارد. دی لانگ گفت: «مغز صرفا یک ماشین پیشخور نیست. در مغز تقریبا به همان اندازه که سیگنالینگ پیشخور وجود دارد، بازخورد وجود دارد».
بنابراین، دانشمندان علوم اعصاب به مدل دیگری روی آورند که شبکه عصبی بازگشتی (RNN) نام دارد. بهگفتهی کاناکا راجان، عصبشناس محاسباتی و استادیار مدرسه پزشکی آیکان در مانتساینای در نیویورک که آزمایشگاه او از شبکههای عصبی بازگشتی برای درک عملکرد مغز استفاده میکند، این شبکهها دارای ویژگیهایی هستند که آنها را به بستری ایدهآل برای مدلسازی مغز تبدیل میکند.
شبکههای عصبی بازگشتی دارای روابط بازخورد و پیشخور بین نورونهای خود هستند و فعالیت مداومی دارند که مستقل از ورودیها است. راجان گفت: «توانایی تولید این پویاییها در مدت زمان طولانی و در عمل، برای همیشه، چیزی است که به این شبکهها توانایی آموزش دیدن را میدهد».
پیشبینی انرژی-کارآمد است
شبکههای عصبی بازگشتی توجه ویلیام لاتر و اساتید مشاور رساله دکترای او یعنی دیوید کاکس و گابریل کریمن را در دانشگاه هاروارد به خود جلب کرد. این تیم در سال ۲۰۱۶، نوعی شبکه عصبی بازگشتی را به نمایش گذاشتند که یاد گرفت فریم بعدی را در سکانس ویدئویی پیشبینی کند. آنها آن را PredNet نامیدند.
پژوهشگران شبکه خود را مطابق با اصول کدگذاری پیشبینانه بهعنوان سلسله مراتبی از چهار لایه طراحی کردند که هریک ورودیهایی را از لایه زیرین پیشبینی میکرد و درصورت عدم تطابق، سیگنال خطایی به بالا ارسال میکرد. آنها سپس شبکه را با ویدئوهایی از خیابانهای شهر که از دوربین نصبشده روی یک خودرو گرفته شده بود، آموزش دادند. پردنت، یاد گرفت که بهطور پیوسته فریم بعدی ویدئو را پیشبینی کند. لاتر گفت: «نمیدانستیم که واقعا کار خواهد کرد یا نه. ما آن را امتحان کردیم و دیدیم که واقعا پیشبینی میکند. خیلی جالب بود».
مرحلهی بعدی ارتباط دادن پردنت با علوم اعصاب بود. سال گذشته در مجلهی Nature Machine Intelligence، لاتر و همکارانش گزارش کردند که پردنت رفتارهای مشاهدهشده در مغز میمونها را در پاسخ به محرک غیرمنتظره نشان میدهد؛ ازجمله برخی موارد که تکرار آنها در شبکههای پیشخور ساده دشوار است.
کیتزمن درباره پردنت گفت: «کار فوقالعادهای است». اما او، مارسل ونگرون و همکارانشان در دانشگاه رادبود در پی مدل اساسیتری بودند: هم مدل رائو و بالارد و هم مدل پردنت بهطور صریح نورونهای مصنوعی را برای پیشبینی و تصحیح خطا همراه با مکانیسمهایی که موجب تصحیح پیشبینیهای بالا به پایین برای جلوگیری از خطای نورونها میشوند، وارد مدل میکنند. اما اگر موارد مذکور به صراحت تعریف نشده بودند، چه؟ کیتزمن میگوید: «فکر میکردیم که آیا تمام این محدودیتهای معماری ثابت واقعا نیاز هستند یا اینکه با رویکرد سادهتری هم میتوانیم پیش برویم».
چیزی که به ذهن کیتزمن و ون گرون رسید، این بود که ارتباطات عصبی ازنظر انرژی هزینهبر است (مغز انرژیخواهترین عضو بدن است). بنابراین، نیاز به صرفهجویی در انرژی ممکن است رفتار هر شبکه عصبی درحال تکامل در موجودات زنده را محدود کند.
پژوهشگران تصمیم گرفتند تا ببینند که آیا مکانیسمهای محاسباتی کدگذاری پیشبینانه ممکن است در شبکه عصبی آنها ظاهر شود که باید وظایف خود را با کمترین انرژی ممکن انجام میداد. آنها دریافتند که مقادیر اتصالات بین نورونهای مصنوعی در شبکهها که «وزن» نامیده میشوند، میتواند بهعنوان جایگزینی از انتقال سیناپسی عمل کند. انتقال سیناپسی پدیدهای است که بیشتر مصرف انرژی را در نورونهای زیستی به خود اختصاص میدهد. کیتزمن میگوید: «اگر وزن بین واحدهای مصنوعی را کم کنید، به این معنا است که با انرژی کمتری ارتباط برقرار میکنید. ما این پدیده را «به حداقل رساندن انتقال سیناپسی» میدانیم».
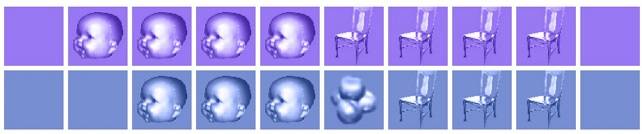
وقتی به PredNet، شبکه عصبی با معماری کدگذاری پیشبینانه، فریمهایی از یک سکانس ویدئویی ارائه شد، (بالا)، شبکه یاد گرفت که آنها را پیشبینی کند (پایین).
سپس پژوهشگران شبکه عصبی بازگشتی را با استفاده توالی بزرگی از ارقام دارای ترتیب صعودی آموزش دادند. هر عدد در قالب تصویر ۲۸ * ۲۸ پیکسل به شبکه نشان داده شد. شبکه شبکه عصبی بازگشتی مدل درونی را فراگرفت که میتوانست رقم بعدی را پیشبینی کند که از هر مکان تصادفی در توالی اعداد میتوانست شروع شود. اما شبکه مجبور شد این کار را با کوچکترین وزنهای ممکن بین واحدها انجام دهد، یعنی شبیه سطوح پایین فعالیت عصبی در سیستمهای عصبی زیستی.
تحت این شرایط، شبکه عصبی بازگشتی یاد گرفت که عدد بعدی را پیشبینی کند. برخی از نورونهای مصنوعی آن بهعنوان واحد پیشبینی عمل کردند. نورونهای دیگر بهعنوان واحدهای خطا عمل کردند و زمانی بیشترین فعالیت را داشتند که واحدهای پیشبینی هنوز یاد نگرفته بودند عدد بعدی را به درستی پیشبینی کنند. واحدهای خطا زمانی که واحدهای پیشبینی در مسیر عملکرد درست قرار گرفتند، آرام شدند. مهمتر اینکه، شبکه به این علت به این معماری رسید که مجبور بود مصرف انرژی را به حداقل برساند. کیتزمن میگوید: «این یاد میگیرد که به نوعی همان بازدارندگی را انجام دهد که پژوهشگران معمولا به صراحت آن را وارد سیستم میکنند. سیستم ما این کار را بهعنوان کار اضطراری و غیرثابت انجام میدهد تا در مصرف انرژی صرفهجویی کند». نکته اصلی این است که شبکه عصبی که مصرف انرژی را به حداقل میرساند، درنهایت نوعی پردازش پیشبینانه انجام میدهد. برایناساس، مغزهای زیستی نیز احتمالا همین کار را انجام میدهند.
راجان کار کیتزمن را نمونه بسیار خوبی میخواند که نشان میدهد چگونه محدودیتهای بالا به پایین مانند به حداقل رساندن مصرف انرژی میتواند بهطور غیرمستقیم به عملکرد خاصی مانند کدگذاری پیشبینانه منجر شود. این موضوع موجب شد او فکر کند که آیا پیدایش واحدهای خطا و پیشبینی خاصی در RNN میتواند نتیجهی ناخواستهای از این واقعیت باشد که فقط نورونهای موجود در لبهی شبکه ورودیها را دریافت میکردند. او حدس میزند: «اگر ورودیها در سراسر شبکه توزیع شده بودند، جدایی بین واحدهای خطا و واحدهای پیشبینی را پیدا نمیکردیم، اما همچنان شاهد فعالیت پیشبینانه بودیم».
چارچوبی یکپارچه برای رفتارهای مغز
هرچند بینشهای حاصل از مطالعات محاسباتی ممکن است قانعکننده بهنظر برسد، درنهایت فقط شواهدی از مغزهای زنده میتواند دانشمندان علوم اعصاب را درمورد پردازش بیشبیانانه مغز متقاعد کند.
در همین راستا، بلیک ریچادز، عصبشناس و دانشمند کامپیوتر در دانشگاه مکگیل و میلا (مؤسسه هوش مصنوعی کبک) و همکارانشان فرضیههای واضحی را درمورد آنچه باید در مغزهایی که یاد میگیرند درمورد رویدادهای غیرمنتظره پیشبینی کنند، ببینند، تدوین کردند. آنها برای آزمایش فرضیههای خود به پژوهشگران مؤسسه علوم مغز آلن در سیاتل روی آوردند که آزمایشاتی را روی موشها انجام میدادند و همزمان، فعالیت مغز آنها را تحت نظارت داشتند.
از موارد مورد توجه خاص آنها نورونهای هرمی در نئوکورتکس بود که تصور میشود ازنظر تشریحی برای پردازش پیشبینانه مناسب باشند. آنها هم میتوانند سیگنالهای حسی محلی پایین به بالا را از نورونهای مجاور (ازطریق ورودیهایی که به جسم سلولی آنها وارد میشود) و هم سیگنالهای پیشبینی بالا به پایین از نورونهای دورتر (ازطریق دندریتهای رأسی) را دریافت کنند.
به موشها توالیهای زیادی از پچهای گابور (Gabor patches) نشان داده شد که از نوارهای تاریک و روشن تشکیل شده است. هر چهار پچ در هر توالی تقریبا جهتگیری یکسانی داشتند و با تکرار آزمایش، در موشها انتظار دیدن آنها ایجاد شد. سپس پژوهشگران رویداد غیرمنتظرهای را وارد کردند: چهارمین پچ گابور بهطور تصادفی در جهت متفاوتی میچرخید. حیوانات ابتدا متحیر شدند، اما با گذشت زمان توانستند انتظار آن مورد را نیز داشته باشند. در تمام این مدت، پژوهشگران فعالیت مغز موشها را مشاهده میکردند.
پژوهشگران شاهد این مسئله بودند که بسیاری از نورونها به محرک مورد انتظار و محرک غیرمنظره واکنش متفاوتی نشان میدادند. مهمتر اینکه، این تفاوت در سیگنالهای محلی پایین به بالا در روز اول آزمایش قوی بود، اما در روزهای دوم و سوم ضعیف شد. این موضوع نشان میدهد انتظارات تازه شکل گرفته بالا به پایین همانطور که از غیرمنتظره بودن محرک کم میشود، شروع به مهار پاسخ به اطلاعات حسی ورودی میکنند. در همین حین، برعکس این پدیده در دندریتهای راسی اتفاق میافتاد: تفاوت در پاسخ آنها به محرک غیرمنتظره با گذشت زمان افزایش پیدا کرد. بهنظر میرسد این مدارهای عصبی درحال یادگیری بودند تا ویژگیهای رویدادهای غیرمنتظره را بهتر نشان دهند تا دفعه بعد پیشبینی بهتری انجام دهند. ریچاردز گفت: «این مطالعه از این ایده که پدیدهای مانند یادگیری پیشبینانه یا کدگذاری پیشبینانه در نئوکورتکس رخ میدهد، حمایت بیشتری میکند».
درست است که مشاهدات فردی فعالیت عصبی یا رفتار یک حیوان را گاهیاوقات میتوان با مدلهای دیگری از مغز نیز توضیح داد. برای مثال، کاهش پاسخ در نورونها به ورودی یکسان، بهجای اینکه بهعنوان مهار واحدهای خطا تفسیر شود، ممکن است ناشی از فرایند سازگاری باشد. اما، پردازش پیشبینانه چارچوب وحدتبخشی برای توضیح همزمان بسیاری از پدیدهها فراهم میکند، بنابراین بهعنوان تئوری درباره نحوه عملکرد مغز جذابیت دارد. ریچاردز گفت: «فکر میکنم در این مرحله شواهد بسیار قانعکننده است. حاضرم روی این ادعا شرط ببندم».
اشتراک گذاری با دوستان



































